レポート
2024.08.29(木) 公開
Google Cloud Next Tokyo ‘24
DAY2参加レポート

今回は、Google Cloudが日本国内で年1回開催するカンファレンスである、Google Cloud Next Tokyoに参加してきました。ただ、本来であれば8月1日から2日の2日間開催なのですが、時間の都合上8月2日のみの参加となりました。
したがって、2日目に見学した内容をお届けします。

個人的には、Google Cloud Next Tokyoへはコロナ前まで毎年のように参加していたのですが、コロナ後は2023年の回には参加できなかったので、2年ぶりの参加でした。
まず、全体の特徴として、「AIのセッションが非常に多い」ということです。もちろん、以前からAIのセッションもあったものの、分析やアプリ開発が主だった記憶から、今回はAIのセッションが圧倒的に多かった印象が強いです。

タイムテーブルで見ると、赤の(AIと機械学習)マークがAIのセッションですが、毎時間にAIのセッションがありました。ここまで多いと、どのセッションに参加するか非常に悩みますね。
このレポートでは、参加したAIのセッションの中から、興味深かった3つのセッションについて紹介させていただきます。
1. Data × AIでイノベーションを牽引する楽天
こちらは、楽天市場や楽天モバイルを提供する楽天グループ株式会社と、コンサルティングを手がけるアクセンチュア株式会社のセッションです。
楽天グループは、eコマース・ブッキングサービス・ペイメント・携帯電話などの各種サービスを提供しており、それらを統合して楽天エコシステムと呼ばれる経済圏の構築を進めています。
さらに、楽天クラウドサービスを統合して提供し、楽天エコシステムに対して効率性と品質を保証することをビジョンとして示されています。
一方で、社外に提供する前に、楽天グループ社内でのAI-nizationを進めていっています。その全体像として示されたのが、次のスライドでした。
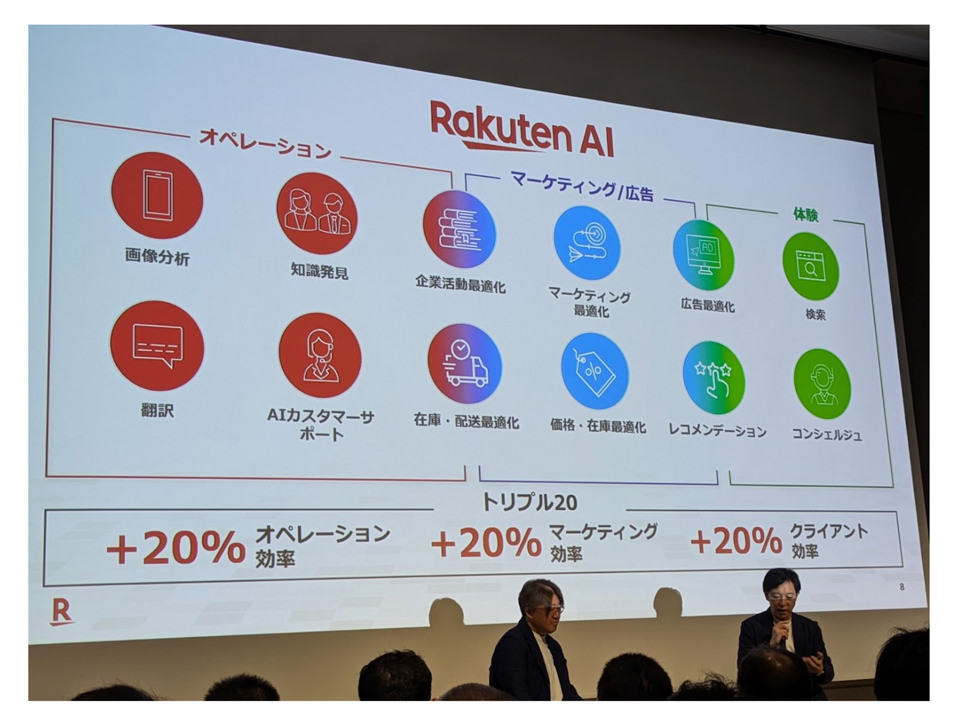
「誰がやってもできる仕事はAIに置き換え、人間はもっと創造的な仕事に時間を使えるようにしていく」というコンセプトのもとで、オペレーション効率・マーケティング効率・クライアント効率を20%向上させる「トリプル20」を達成するために、どのようにやっていくかを楽天グループは考えているそうです。
セッションでも語られていましたが、AIの導入というと「PoCから始まって、本格導入によって改善した」という話はよく聞きますが、そのほとんどが、特定のファンクションやプロセスに閉じた話です。
それに対して、楽天グループは個々のプロセス指標の改善ではなく、全社の指標がターゲットとなっていて、それを経営層が毎月トラッキングをしているそうです。
そのため、コストの付け替えやカニバリによって、個々プロセスでは改善しているように見えて、全社的には改善の影響が見られないといった状況も避けられているようです。
この辺りの考え方は、身につまされるものがあります。
どうしても、AIの導入はまずはやりやすい・効果が出やすいところから、と始めてしまいがちですが、果たして全社で効果が出ているのかが分からないということは私自身も経験があります。
その効果を全社に拡大するために、ボトムアップで草の根的に広げていくことに終始しがちですが、それと同じくらい全社の指標を示すことで、トップダウンで進めていくことの重要性についても考えさせられました。
2. LLM・マルチモーダルプロジェクトにおける多部門展開を成功させるための戦略
続いては、衛生用品の大手メーカーであるユニ・チャーム株式会社と、データ活用のサービスを手がける株式会社ブレインパッドによるセッションです。
こちらでは、社員専用の生成AI-ChatであるUniChatを全社に展開していくための戦略について語られています。
UniChatは、生成AIのブームに合わせて作成したが、当初は社内情報と組み合わせた回答が不十分なこともあり、あまり利用が伸びなかったそうです。
そこで、マルチモーダルAIやRAGといった最新の技術を調査し、法務部門用のAI-Chatとして再スタートしました。
法務部門が選ばれた理由は、危機感が大きく必要性が高い点と、社内への展開がしやすそうという点がありました。
法務部門のPoCとしては、社内のデータを用いてGemini1.0とVertex AI Searchで実装し、上位3件の候補に対しての正答率で91.24%と高い結果を示しました。その結果を受けて、2024年8月中に正式ローンチ予定で、さらに人事・経理・システム部門への展開を検討しています。
一方で、社外データを用いた取り組みについても並行して推進されています。知財部門のPoCがそちらにあたり、クローリングした特許情報を用いて実装を進めています。
その構成図が次のスライドでした。

具体的な実装として、FAQ検索とマニュアル検索+AIによる回答生成を組み合わせることで、整備されているマニュアルを上手く活用して回答の正確性を上げています。
さらに、AIの回答性能を評価するために、LLMで自動評価する機能も実装しており、人の工数削減や評価の揺らぎを解消するといった効果を上げています。
これらの実装の結果、特許要約モデルでは、評価想定として5点満点中、2.5点を目標としていたのに対し、知財部門による評価が2.73点・LLMでの自動評価で2.96点という高い結果を示しました。そのため、こちらも社内利用に向けてリリース準備中です。
ユニ・チャーム株式会社のAI展開は、先ほどの楽天グループに比べると、王道のPoCからの本格リリース、横展開という方法に見えています。
しかし、多くの企業で、PoCで終わってしまいがちなところを、しっかりと「この目標値」というものを定めて、それを達成したら本格リリースをしっかりと行うというルールが明確なため、このように多部門展開を実現できているのではないでしょうか。
また、技術としても単純に生成AIをそのまま使うというだけでなく、マニュアル検索との組み合わせや、自動評価の実施といった多くの場面で活用できそうなものがありました。
ぜひ、この様な展開手法は真似していってみたいと思います。
3. Geminiで実現するマルチモーダル生成AI
最後はGoogle合同会社が自社製品の活用として、マルチモーダルの生成AI構築について話しているセッションです。
先ほどのユニ・チャーム株式会社の生成AI実装でも活用されていたVertex AI Searchを用いた比較的簡易な実装方法とスクラッチでの実装方法について紹介した後、スクラッチでの実装方法についてのポイントを詳しく話しているのが次のスライドです。

マルチモーダル生成AIというと、テキストと画像のどちらもを同時にデータとして用いるもので、上記のアーキテクチャ例では、ユーザーからの質問回答のために、マニュアルのテキストと図の両方から検索して、最適な回答を作り出すことを実現しています。
アーキテクチャのポイント1つ目はマルチモーダルデータの前処理についてです。
テキストのみの生成AIでも、ベクトルDB化するための前処理は重要ですが、マルチモーダルの場合はさらに難易度が挙がります。
前処理のパターンは様々ですが、マルチモーダルLLMによって画像をテキスト化し、マニュアルのテキストと合わせてテキストEmbeddingとしてベクトルDBに登録する方法が示されています。
また、マルチモーダルモデルでは、プロンプトエンジニアリングの重要性も増します。
画像から情報を読み取る際に、単純にOCRのようにデータをテキスト化して回答するのではなく、プロンプトで画像の読み解きプロセスを明記することで、ユーザーからの質問に対してより適切に回答することができるようになります。
しかし、そのためには図やグラフごとに読み解きプロセスを指定するといった、マルチモーダルならではの大変さもあります。
アーキテクチャのポイント2つ目はセキュリティについてです。
生成AIで回答させようとすると、個人情報や機密情報といったもののフィルタが必要となります。マルチモーダルの場合、画像からテキスト化した情報に対して、個人情報・機密情報の除去を行うといった処理を行ていますが、それだけでは対応しきれないケースがあります。
そこで、ユーザーからの質問に対して、事前に用意した危険性がある・不適切なプロンプトとの類似度を計算し、個人情報や機密情報にアクセスを試みるような質問に対しては、適宜フィルタ等を適用するといったことも行っています。
4. まとめ
今回参加した様々なセッションで、生成AIを自社内外での活用を進めていくということが、かなり広まってきていることを実感しました。また、Google CloudのVertex AIやGeminiおよび、それらに付随するサービスによって、簡易なものであれば比較的容易に実装することも可能だということを理解しました。
一方で、多くの事例でもありましたが、生成AIを業務に活用するためには、重要となるデータをどう整備していくべきか、どの技術を用いるべきかを専門家と相談しながら進めることが重要であることも再認識させられました。
NOB DATAでは、これまでも様々な企業に生成AIに関するシステムや、サービスを導入してきました。
今回、Google Cloud Nextで紹介されているようなツール・サービスによって、開発工数の削減やUI/UX、セキュリティなど幅広い事象への対応など、多くのメリットを感じることができました。
改めて、これらのツール・サービスについても、学びを深めていくことで、よりよい生成AIに関するシステム・サービスを提供しています。
この記事の著者

データサイエンティスト
烏谷 正彦
AI系のスタートアップ企業で、データサイエンティストとしてビッグデータを用いたアナリティクスを提供。現在は、生成AIのソリューションや教育を提供するフリーランスとして活動。最近の趣味は、銭湯に向けてランニングをすること。NOB DATAでは、生成AIまわりのリサーチや情報発信を担当。
関連サービス

