レポート
2026.05.27(水) 公開
【2026年最新動向】オープンソースTTS技術の進化と主要モデル徹底解説

目次
1. はじめに
音声合成技術(TTS:Text-to-Speech)は、2026年に入り劇的な進化を遂げています。わずか3秒の音声サンプルで特定の声をクローンでき、推論速度97msという超低遅延を実現し、感情表現や非言語音まで制御できる時代が到来しました。これらの高度な機能は、かつて商用サービスの独占領域でしたが、今やオープンソースモデルで誰でも無料で利用できるようになっています。
本記事では、2026年のオープンソースTTS技術の最新動向を徹底解説します。具体的には、LLMベースモデルの台頭やゼロショット音声クローニングの実用化といった最新トレンド、主要5モデルの技術比較、日本語対応の現状、そして2026年1月発表の最新モデルQwen3-TTSをブラウザだけで体験する実践手順を紹介します。
この記事を読むことで、最新のオープンソースTTS技術を理解し、自分のプロジェクトに最適なモデルを選定でき、すぐに実践できる知識を得られます。それでは、2026年のオープンソースTTS最前線を見ていきましょう。
2. 2026年のTTS技術トレンド
2026年のオープンソースTTS業界は、技術的な転換点を迎えています。本章では、業界を特徴づける4つの主要トレンドを解説します。
2.1 LLMベースTTSモデルの台頭
2026年最大のトレンドは、大規模言語モデルをベースにしたTTSの登場です。Llama 3.2をベースとするHiggs Audio V2は57億パラメータを持ち、従来のVITS系モデルとは異なるアーキテクチャで音声生成を行います。Orpheusも3億から30億パラメータのLLMベースモデルで、テキスト理解と音声生成を統合的に処理できます。
これらのモデルは文脈理解が深く、長文でも自然なイントネーションを維持できる利点があります。感情の一貫性や話者の個性表現が向上しており、複雑な対話文や物語の読み上げでも話者の特徴を維持できます。
2.2 ゼロショット音声クローニングの実用化
ゼロショット音声クローニングは、事前学習なしで新しい話者の声を再現する技術で、2026年に実用レベルに到達しました。XTTS-v2はわずか6秒の音声サンプルで特定の声質を学習し、多言語での音声生成が可能です。2026年1月に発表されたQwen3-TTSは、わずか3秒の音声サンプルでボイスクローニングを実現し、推論速度も97msと超低遅延を達成しています。
この技術革新により、従来は数時間の音声データと学習時間が必要だったカスタム音声作成が、数秒で完了するようになりました。応用範囲は広く、企業のブランド音声作成、パーソナライズされた音声アシスタント、教育コンテンツのナレーション多様化など、多岐にわたります。
2.3 感情表現と非言語音の高度化
2026年のTTSモデルは、単なる言葉の読み上げを超えて、笑い声・ため息・咳・間の取り方など非言語音を制御できるようになっています。Diaはテキスト中に特殊タグを埋め込むことで非言語音を挿入でき、会話の臨場感を大幅に向上させます。
Style-Bert-VITS2 JP-Extraは日本語に特化し、テキストの内容から自動的に感情を推定して音声に反映する機能を持ちます。感情の強弱をスライダーで調整でき、楽しそうな声・悲しそうな声・怒った声などを手動で指定することも可能です。この技術進化により、ゲームキャラクター音声やオーディオブックの表現力が飛躍的に向上しています。
2.4 日本語対応モデルの進化
日本語に対応したオープンソースTTSは、2024年から2026年にかけて大きく進化しました。VOICEVOXは日本国内で最も普及したTTSツールとなり、YouTubeクリエイターや教育現場での利用が拡大しています。Style-Bert-VITS2は2024年2月にJP-Extraバージョンをリリースし、日本語の発音精度・アクセント・セリフの読み上げ品質が大幅に向上しました。
2026年1月にはQwen3-TTSが登場し、10言語に対応しながら高品質な音声生成を実現しています。2026年現在、日本語特化モデルと多言語モデルの品質差は縮小傾向にあり、用途に応じて使い分けられる環境が整っています。
3. 注目の最新オープンソースTTSモデル【比較表あり】
2026年にリリースまたは注目を集めている最新モデルを紹介します。
3.1 Higgs Audio V2:57億パラメータの大規模モデル
Higgs Audio V2はLlama 3.2をベースとする大規模TTSモデルで、57億パラメータを持つ2026年最大級のオープンソースTTSです。大規模パラメータによる文脈理解力が最大の強みで、長文の読み上げでも自然なイントネーション・感情の一貫性を維持できます。
ただし、推論にはGPU(最低VRAM 8GB以上推奨)が必要で、計算コストが高い点が課題です。研究機関やハイエンドな商用プロジェクト、高品質なオーディオブック制作などでの活用が想定されています。
3.2 Chatterbox:小型・高速・高品質の新星
Chatterboxは2025年5月にResemble AIが発表したTTSモデルで、2026年に入り開発者コミュニティで急速に普及しています。わずか5億パラメータという小型設計ながら、ElevenLabsやOpenAI TTSといった商用サービスに匹敵する品質を実現しています。
MITライセンスで完全無料、多言語対応、ゼロショット音声クローニング対応と、機能面でも充実しています。推論速度が速く、実験・プロトタイピング・小規模プロジェクト・個人開発者にとって最適な選択肢となっています。
3.3 Qwen3-TTS:3秒でボイスクローンする超低遅延モデル
Qwen3-TTSは2026年1月22日にAlibaba Cloudが発表した最新の多言語TTSモデルです。わずか3秒の音声サンプルでボイスクローニングが可能で、推論時間は97msと超低遅延を実現しています。
10言語(中国語・英語・日本語・韓国語・フランス語・ドイツ語・イタリア語・スペイン語・ポルトガル語・ロシア語)に対応し、感情表現やスタイル転送にも対応しています。Apache 2.0ライセンスで商用利用可能、HuggingFaceでモデルとデモが公開されており、ブラウザから即座に試すことができます。2026年最大の技術革新として注目されています。
3.4 Orpheus:LLMベースの次世代TTS
OrpheusはLLMベースのTTSモデルで、3億・10億・30億パラメータの3つのバリエーションが提供されています。言語理解と音声生成を統合したアーキテクチャを採用し、テキストの意味を深く理解した上で音声化できる点が強みです。
特に会話型AIや対話システムとの統合に適しており、文脈に応じた自然な応答音声を生成できます。Apache 2.0ライセンスで商用利用可能、APIサーバー形式での提供も容易なため、プロダクション環境での採用事例が増えています。
3.5 Dia:非言語音に対応した表現力
Diaは2025年後半に登場した、非言語音に対応した先進的なTTSモデルです。テキスト中にタグを埋め込むことで、笑い声・息を呑む音・ため息・咳などの非言語音を音声に挿入できます。
会話の臨場感やリアリティが大幅に向上し、ゲーム・アニメーション・オーディオブック・ボイスドラマなどのエンターテインメント分野での活用が期待されています。現時点ではベータ版として一部の開発者に提供されており、2026年半ばの正式リリースが予定されています。
3.6 主要モデルの技術比較
2026年の主要オープンソースTTSモデルを技術的観点で比較します。
横スワイプで続きを御覧ください
4. 日本語対応オープンソースTTS最新状況
日本語に対応したTTSツールは、国内開発モデルと海外多言語モデルの2つの軸で進化しています。
4.1 VOICEVOX:国内シェアNo.1の現状
VOICEVOXは2021年の登場以降、日本国内で最も広く使われているオープンソースTTSツールです。2026年現在も活発に開発が続けられ、キャラクター音声の追加・音質改善・機能拡張が定期的に行われています。
最大の強みは、プログラミング知識不要でGUI操作だけで高品質な音声を生成できる点です。ずんだもん・四国めたんなどのキャラクター音声は、YouTube動画・ゲーム・教育コンテンツで広く活用されています。商用利用は無料ですがクレジット表記が必須で、各キャラクターごとに利用規約が異なる点には注意が必要です。
4.2 Style-Bert-VITS2 JP-Extra:感情表現の最高峰
Style-Bert-VITS2 JP-Extraは、日本語TTSにおいて最高レベルの自然さと感情表現を実現するモデルです。2024年2月にリリースされたJP-Extraバージョンでは、日本語の発音精度が大幅に向上し、複雑なセリフ・長文・感情的なニュアンスを含むテキストでも自然に読み上げられるようになりました。
技術的には、BERTによる言語理解とVITS2による音声生成を組み合わせ、テキストの意味内容から自動的に感情を推定します。手動での感情・スタイル指定も可能で、Neutral・Joyful・Sad・Angryなどのカスタムスタイルを学習させることもできます。
4.3 多言語モデルの日本語対応状況
海外で開発された多言語TTSモデルも、日本語対応を強化しています。Chatterboxは日本語を含む10言語以上に対応し、日本語の音声品質は実用レベルに達しています。XTTS-v2は17言語対応で日本語も含まれており、クロスリンガル音声転送も可能です。
2026年1月に登場したQwen3-TTSは、10言語対応で日本語の品質も高く、3秒のサンプルでボイスクローニングが可能です。これらのモデルは一つの環境で複数言語を扱えるメリットがあり、グローバル展開するプロジェクトに適しています。
4.4 日本語特化 vs 多言語モデルの品質比較
日本語特化モデル(VOICEVOX、Style-Bert-VITS2)は、発音精度・アクセント・イントネーションの自然さで優位性があります。一方、多言語モデルは単一の環境で複数言語を扱える利便性があり、言語間での音声品質の一貫性を保てます。
2026年時点では、日本語特化モデルの品質優位性は依然として存在しますが、Qwen3-TTSなど最新の多言語モデルの急速な品質向上により、その差は縮小傾向にあります。純粋な日本語コンテンツ制作ならStyle-Bert-VITS2、多言語展開を見据えるならQwen3-TTSという選択が一般的です。
5. 【実践】最新モデルQwen3-TTSをブラウザで試す
2026年1月に発表されたQwen3-TTSは、3秒でボイスクローニングが可能な最新モデルです。HuggingFace Spacesを使えば、プログラミング不要・インストール不要で、ブラウザから直接体験できます。
5.1 Qwen3-TTSとは
Qwen3-TTSは、Alibaba Cloudが2026年1月22日に発表した多言語対応の音声合成モデルです。わずか3秒の音声サンプルでボイスクローニングが可能で、推論速度97msという超低遅延を実現しています。10言語に対応し、感情表現やスタイル転送も可能です。Apache 2.0ライセンスで商用利用も無料で、HuggingFaceで公式デモが公開されています。
5.2 HuggingFace Spacesでのアクセス方法
HuggingFace Spacesは、機械学習モデルをブラウザから直接試せるプラットフォームです。登録不要・無料で利用でき、サーバー側で推論が実行されるため、自分のPCスペックに関係なく最新モデルを体験できます。
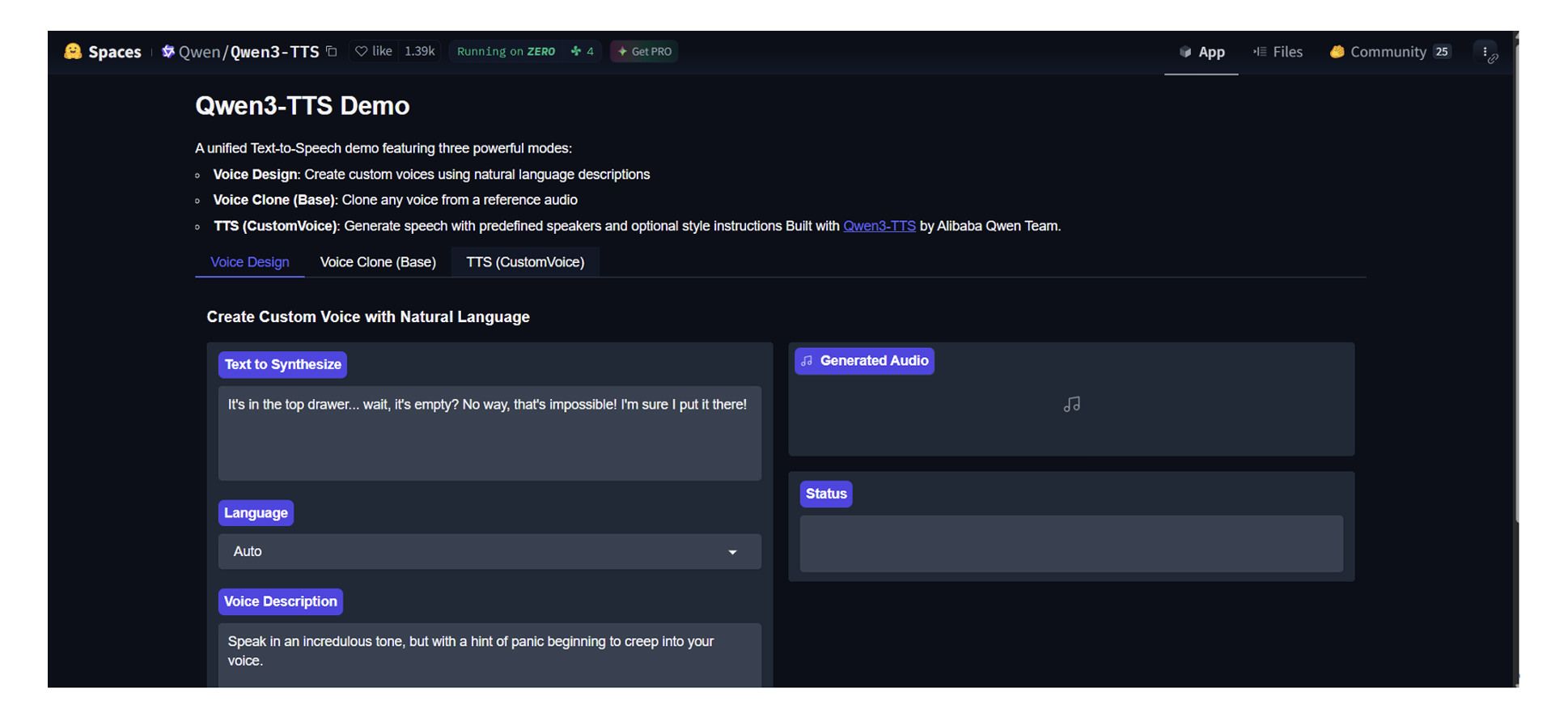
Qwen3-TTSのデモページhttps://huggingface.co/spaces/Qwen/Qwen3-TTSにアクセスすると、シンプルで直感的なインターフェースが表示されます。画面には言語選択ドロップダウン、中央にテキスト入力欄、下部に音声アップロード欄が配置されています。
5.3 基本的な音声生成の手順
基本的な音声生成を試してみます。手順は以下の通りです。
-
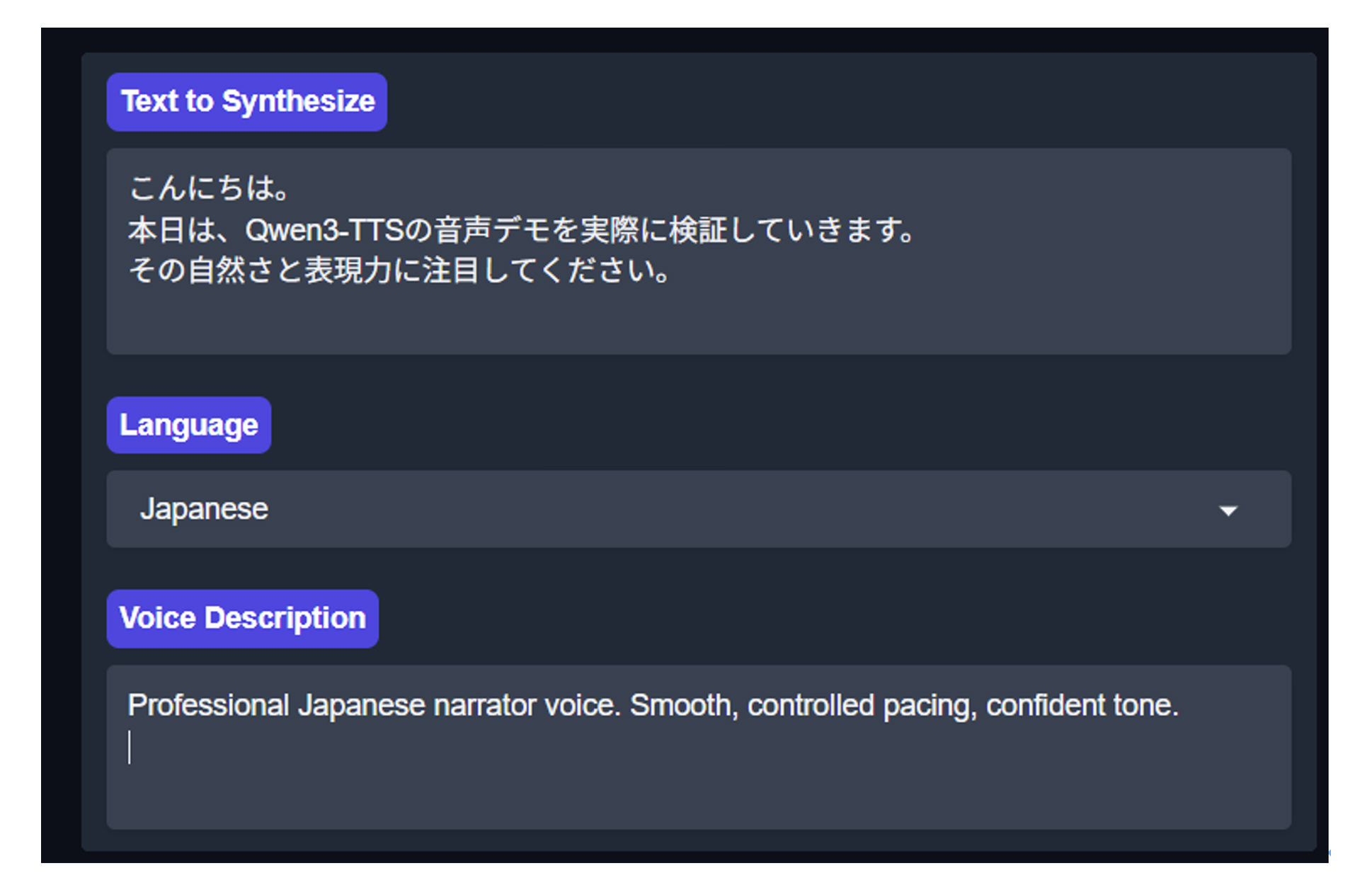
言語選択ドロップダウンから「Japanese」を選択する
-
テキスト入力欄にテキストを入力する
-
音声アップロード欄は空のまま(デフォルト音声を使用)
-
「Generate」ボタンをクリックする
97msという超低遅延のため、クリックしてから1秒以内に音声が生成されます。生成された音声は画面上で即座に再生でき、音質・発音・イントネーションを確認できます。
5.4 3秒音声クローニングの実験
Qwen3-TTSの最大の特徴である、3秒音声クローニングを試してみます。手順は以下の通りです。
-
参照音声(WAVまたはMP3ファイル、3秒以上)を準備する
-
「Upload reference audio」ボタンをクリックし、ファイルをアップロードする
-
テキスト入力欄に生成したい内容を入力する
-
言語を選択する(参照音声と同じ言語でも、異なる言語でも可能)
-
「Generate with voice cloning」ボタンをクリックする
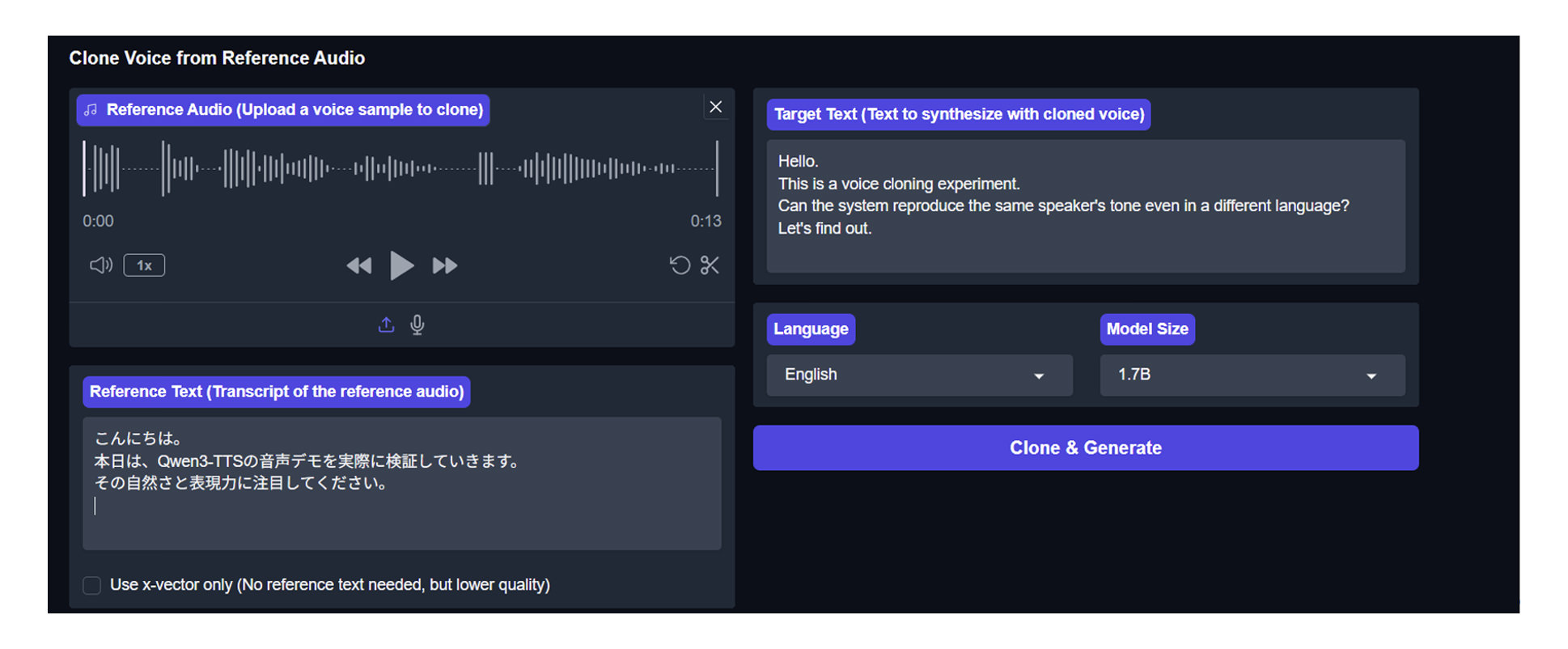
わずか数秒の音声サンプルから声質を学習し、新しいテキストをその声で読み上げます。クロスリンガル音声転送にも対応しているため、例えば日本語の参照音声を使って英語テキストを生成することも可能です。
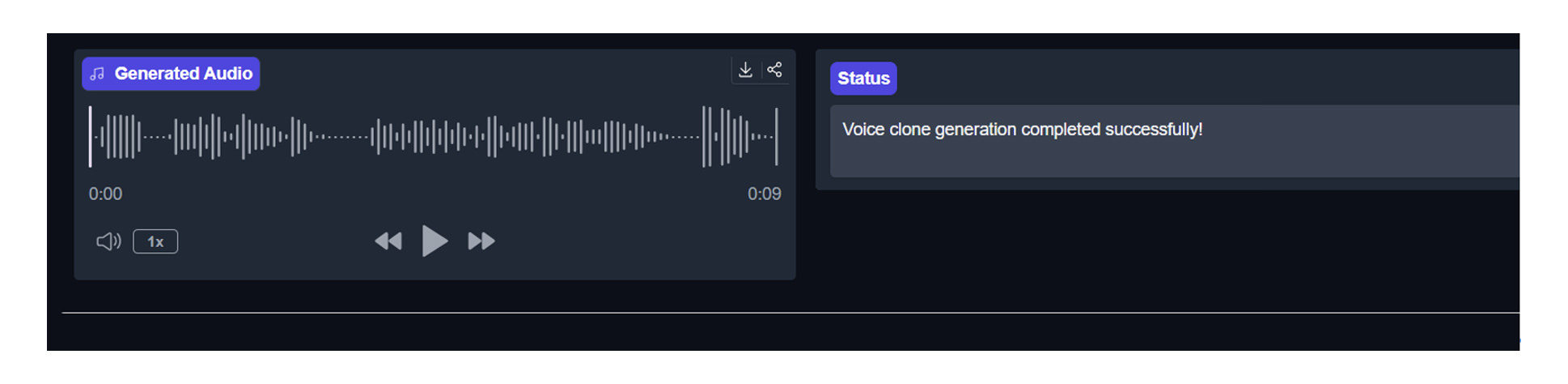
5.5 生成音声のダウンロードと活用
生成された音声は、画面下部の「Download」ボタンからWAVファイルとしてダウンロードできます。
ダウンロードした音声は、動画編集ソフトでのナレーション、プレゼンテーション音声、ポッドキャスト制作、e-ラーニング、ゲーム内音声ガイドなど、さまざまな用途で活用できます。Apache 2.0ライセンスのため、商用利用も自由です。ただし、音声クローニング機能を使う際は、元の声の所有者から許可を得ることが倫理的・法的に必須です。
6. 技術的ブレイクスルーと今後の展望
2026年に起きた技術革新と、今後数年間のTTS技術の進化方向を分析します。
6.1 パラメータ効率と品質のトレードオフ
2026年の大きなトレンドは、小型モデルでの高品質化です。Chatterboxは5億パラメータで商用サービス並みの品質を実現し、パラメータ数が多ければ良いという従来の考え方を覆しました。Qwen3-TTSも比較的小型ながら、97msという超低遅延と高品質を両立しています。
これは、学習データの質向上、アーキテクチャの最適化、知識蒸留技術の進展によるものです。一方で、Higgs Audio V2のような大規模モデルは、文脈理解・長文での一貫性・複雑な感情表現で優位性を持ちます。2026年後半から2027年にかけて、10億~30億パラメータのミドルサイズ高品質モデルが主流になると予想されています。
6.2 商用モデルとの品質差縮小
2026年現在、オープンソースTTSと商用サービスの品質差は急速に縮小しています。Chatterboxの評価ではElevenLabsと同等とされ、実用レベルでは差がほとんどないケースも増えています。Qwen3-TTSは推論速度97msを達成し、レスポンス速度では多くの商用サービスを上回ります。
商用サービスは依然として音声バリエーションの豊富さ、細かいニュアンス表現、安定性とサポート体制で優位性を持ちますが、オープンソースモデルも急速にキャッチアップしています。2027年には、特定用途ではオープンソースが商用を上回る可能性もあります。
6.3 エッジデバイス対応の進展
エッジデバイス(スマートフォン・IoT機器・組み込みシステム)での音声合成が現実的になりつつあります。MeloTTSはCPU環境でのリアルタイム推論を実現し、GPU不要で動作します。
量子化・プルーニング・知識蒸留などのモデル圧縮技術が進展し、5億パラメータ以下のモデルをモバイルデバイスで動かす試みが始まっています。Qwen3-TTSの97msという超低遅延は、エッジデバイスでのリアルタイム対話にも応用可能です。オフライン音声アシスタントなど、新しい用途が開拓されています。
6.4 2026年後半の注目トレンド
2026年後半から2027年初頭にかけて、以下のトレンドが予想されます。
-
リアルタイム対話TTSの進化:100ms以下の推論時間が標準となり、ストリーミングTTSが実用化される
-
感情認識とTTSの統合:ユーザーの感情状態を自動認識し、それに応じた音声応答が可能になる
-
マルチモーダル統合:画像・動画・テキストから音声を生成する技術が実用化される
-
倫理的利用の標準化:音声透かし技術、生成検出システム、なりすまし防止技術が標準化される
7. 用途別モデル選定ガイド
プロジェクトの目的に応じた最適なTTSモデルの選び方を解説します。
7.1 開発プロジェクト向け選定基準
アプリ・サービス開発で組み込むTTSを選ぶ際は、ライセンス・推論速度・API化のしやすさが重要です。推奨モデルはChatterboxまたはQwen3-TTSで、どちらもMITまたはApache 2.0ライセンスで商用利用の制約が少なく、自由に組み込めます。
Chatterboxは推論速度が速くリアルタイム応答が求められるチャットボットに適し、Qwen3-TTSは97msの超低遅延で音声対話システムに最適です。XTTS-v2は17言語対応でグローバル展開プロジェクトに向きます。
7.2 コンテンツ制作向け選定基準
動画ナレーション・オーディオブック・ポッドキャストなどのコンテンツ制作では、音声品質・感情表現・操作性が重視されます。日本語コンテンツならVOICEVOXまたはStyle-Bert-VITS2が最適です。
VOICEVOXはGUI操作で簡単に使え、キャラクター性のある音声が必要な場合に最適です。Style-Bert-VITS2は感情豊かな表現が可能で、ドラマ性のあるコンテンツに向いています。英語・多言語コンテンツならChatterboxまたはQwen3-TTSが推奨されます。
7.3 研究・実験向け選定基準
研究目的や技術検証では、モデルのカスタマイズ性・コミュニティの活発さ・ドキュメント充実度が重要です。日本語研究ならStyle-Bert-VITS2が推奨され、カスタムモデルの学習手順やスタイル制御の実験に適しています。
最新技術研究ならQwen3-TTSが向いており、ゼロショット音声クローニングや超低遅延推論の研究に最適です。LLMベース研究ならOrpheusが適しており、大規模モデル研究ならHiggs Audio V2が推奨されます。
8. よくある質問(FAQ)
8.1 オープンソースは商用モデルに追いついたのか
2026年時点では、特定の用途・言語においてオープンソースが商用モデルに匹敵またはそれを上回るケースが出ています。ChatterboxはElevenLabsと同等と評価され、Qwen3-TTSは推論速度で多くの商用サービスを上回ります。
ただし、商用サービスは音声バリエーションの豊富さ、安定性、サポート体制で依然として優位性があります。コスト・カスタマイズ性・プライバシーを重視するならオープンソース、手軽さ・安定性を重視するなら商用サービスが適しています。
8.2 ゼロショット音声クローンの精度は
ゼロショット音声クローニングの精度は2026年に実用レベルに到達しました。XTTS-v2は6秒の音声サンプルで高精度な声質再現が可能で、Qwen3-TTSはわずか3秒のサンプルでボイスクローニングを実現しています。
音質の類似度では0.85~0.90(1.0が完全一致)を達成しており、人間の耳では元の声とほぼ区別がつかないレベルです。ただし、音声サンプルの品質(ノイズ・音量・明瞭さ)に大きく依存します。
8.3 日本語品質は実用レベルか
日本語特化モデル(VOICEVOX、Style-Bert-VITS2)は完全に実用レベルに達しており、商用コンテンツでも広く利用されています。多言語モデルの日本語品質も実用レベルですが、アクセント・イントネーションの自然さでは日本語特化モデルにやや劣ります。
2026年1月に登場したQwen3-TTSは、多言語モデルでありながら日本語の品質が高く、品質差は縮小傾向にあります。動画ナレーション・教育コンテンツ・アプリの音声ガイドなど、多様な用途で実際に活用されています。
8.4 今後どのような進化が予想されるか
2027年以降、以下の進化が予想されます。
-
超低遅延化の標準化:100ms以下の推論時間が一般的になり、人間の反応時間を下回る応答が可能に
-
詳細な音声制御:年齢・性別・性格・話し方のクセまで指定できる完全カスタマイズ可能な音声が実現
-
Voice-to-Voiceの進化:自分の声で話した内容を別の声質・言語で出力することがリアルタイムで可能に
-
倫理的対策の強化:音声透かし、生成検出、なりすまし防止技術が標準化される
-
マルチモーダル統合:画像・動画から音声を自動生成する技術が実用化される
9. まとめ
2026年のオープンソースTTS技術は、商用サービスに匹敵する品質と機能を実現し、実用段階に到達しました。LLMベースモデルの登場により文脈理解が深化し、わずか3秒でボイスクローニングが可能になり、感情表現と非言語音の制御が高度化するなど、技術的なブレイクスルーが相次いでいます。
特に注目すべきは、Qwen3-TTSの97ms推論とChatterboxの小型高品質化です。日本語対応も進化し、VOICEVOXとStyle-Bert-VITS2が国内市場を牽引する一方、多言語モデルの日本語品質も急速に向上しています。
用途に応じた最適なモデル選定が可能になり、開発プロジェクトにはQwen3-TTSやChatterbox、コンテンツ制作にはVOICEVOXやStyle-Bert-VITS2、研究にはOrpheusやHiggs Audio V2という使い分けができます。HuggingFace Spacesの普及により、誰でもブラウザから最新技術を体験できる環境が整いました。
2027年以降は、100ms以下の超低遅延の標準化、詳細な感情・パーソナリティ制御、Voice-to-Voiceの進化、倫理的対策の強化、マルチモーダル統合が予想されます。オープンソースTTSは、コスト・カスタマイズ性・プライバシー保護の観点で商用サービスに代わる有力な選択肢となり、今後も急速な進化が期待されます。
10. 参考文献
The Top Open-Source Text to Speech (TTS) Models
6 Popular Open-Source Text-to-Speech Models in 2026
The Best Open-Source Text-to-Speech Models in 2026 - BentoML
Style-)Bert-VITS2 JP-Extra で...
GitHub - litagin02/Style-Bert-VITS2
【商用利用可&無料】AI音声合成ツール"VOICEVOX"の強みからおすすめの方まで徹底解説
【2026年版】文字を音声化するには?音声合成サイト・ソフト7種類...
【2026年版】音声読み上げソフト10選!商用OKのおすすめサービス...
Chatterbox Multilingual:聴覚体験を覆すオープンソース音声AI
日本語を含む10言語に対応した音声生成モデル「Qwen3-TTS Family」がオープンソース化
Qwen3-TTSってなんだ?〜3秒の音声でボイスクローンできる最新音声合成AI〜
Qwen3-TTSってなんだ?〜3秒の音声でボイスクローンできる最新音声合成AI〜
「ChatGPT導入・活用支援」はNOB DATAにご相談ください
ChatGPTの導入・活用に課題を感じていませんか?
NOB DATAでは、ChatGPT開発およびデータ分析・AI開発のプロフェッショナルが、多種多様な業界・課題解決に取り組んだ実績を踏まえ、ChatGPTの導入・活用を支援しています。社員向けのChatGPT研修も実施しており、お気軽にお問い合わせください。