レポート
2024.10.04(金) 公開
データの前処理
本記事ではChatGPT上でのデータの前処理について解説します。
前処理は、データ分析の鍵を握る重要なステップです。今回は、ChatGPTを用いてデータの前処理をどのように行うかを解説します。まずは、例として使用するデータをアップロードしましょう。
1. データのアップロード
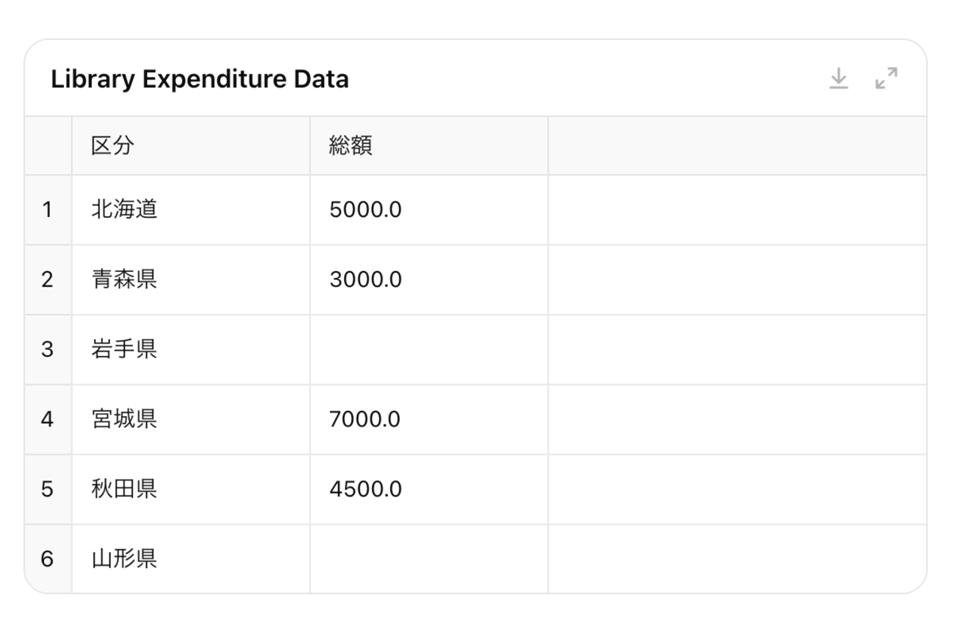
前処理を実行するためのサンプルデータをアップロードします。実データが手元にある場合は、この作業は不要です。今回はデータ前処理の具体例として、「図書館の支出データ」を準備しました。下記リンクからダウンロードしてください。
データセットの前提条件として、以下のデータの情報・状態を以下の通りとします。
- 区分: 都道府県
- 総額: 図書館に関する費用の総額
- 欠損値:あり
2. ChatGPT上での前処理の実行例
このデータの総額には欠損値が含まれています。データの前処理の一つとして欠損値への対応があります。
まずは欠損値の個数をカウントしましょう。

このデータには「総額」の列に欠損値が3つ含まれていることがわかりました。
分析の目的によって、この欠損値の処理には様々な方法が考えられますが、今回は平均値で欠損値を埋める「平均値補完」を実行しましょう。
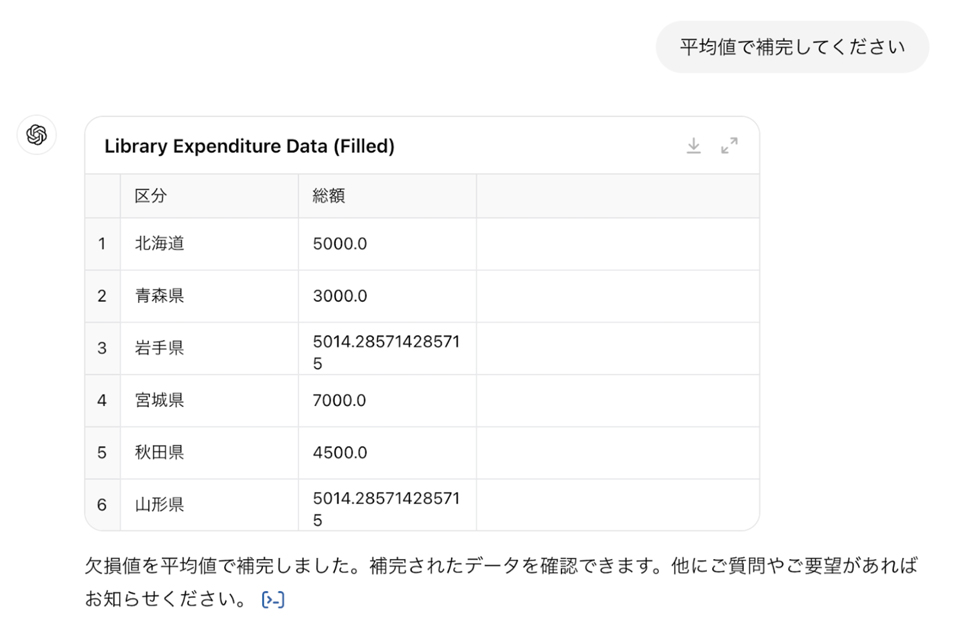
これで欠損値を平均値で補完できました。
前処理はデータの状態を確認しながら、分析の目的に沿った手法を取る必要があります。どのような状況でどのような前処理を選ぶかについては、下記書籍などを参考にしてください。
【参考記事】
この記事の著者

データサイエンティスト
市川 太祐
医師・医学博士。名古屋市立大学客員准教授。データサイエンティスト。データを用いた意思決定に長年取り組む。予防医療から電子カルテデータ、ライフログデータまで幅広い分析経験を持つ。「R言語徹底解説」(共立出版)、「データ分析プロジェクトの手引き」 (共立出版)等、データ分析関連の著書・訳書多数。
「ChatGPT導入・活用支援」はNOB DATAにご相談ください
ChatGPTの導入・活用に課題を感じていませんか?
NOB DATAでは、ChatGPT開発およびデータ分析・AI開発のプロフェッショナルが、多種多様な業界・課題解決に取り組んだ実績を踏まえ、ChatGPTの導入・活用を支援しています。社員向けのChatGPT研修も実施しており、お気軽にお問い合わせください。
ChatGPTを使ったデータ分析の基本