レポート
2024.10.04(金) 公開
高度な分析
本記事ではChatGPT上で高度な分析を実行する方法について解説します。
まずは、例として使用するデータを準備しましょう。
1. データのアップロード
この分析で用いるデータを下記からダウンロードしてください。
今回は、具体例として「親子の身長に関するデータ」を準備しました。データセットの前提条件として、データの情報を以下の通りとします。
- 子供の身長
- 親の身長
一般に親子の身長は、親の身長が高ければ子の身長も高いというように相関関係にあると言われているため、その事実をふまえたデータとしています。
2. データの相関関係を分析する
ChatGPTを用いた高度な分析の一つとして、データの相関を分析してみましょう。
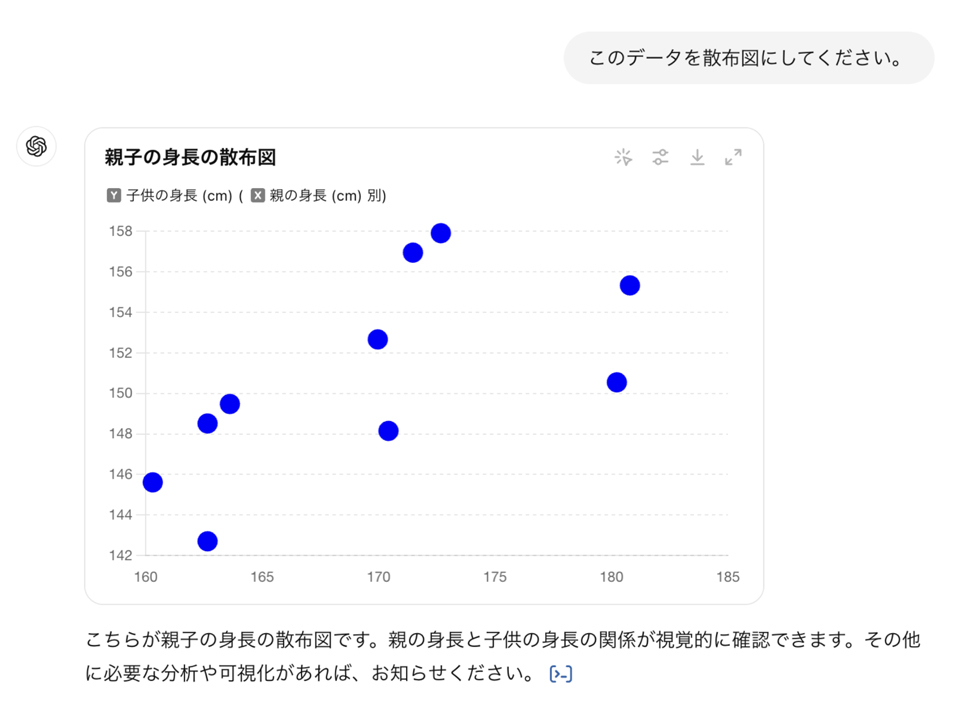
2.1. 散布図
まずは散布図でデータを可視化します。
2.2. 相関係数の算出
親子の身長について相関係数を計算してみましょう。

相関係数が0.65という結果が得られました。
2.3. 回帰分析
親の身長が1cm増加すると子の身長がどの程度増加しうるか、回帰分析で検証してみましょう。

回帰分析を実行し、親の身長が子の身長に与える影響を定量化できました。
3. ChatGPT-4oで可能な分析手法の例
ChatGPT-4oで分析可能な機械学習手法の例を以下に示します。
横スワイプで続きを御覧ください
表1 ChatGPT-4oで利用可能な機械学習手法ChatGPT-4oではPythonのstatsmodelやscikit-learn等のライブラリを用いて高度な統計分析を実行します。上記以外のどのような分析が可能かについては、これらのライブラリの公式サイトを確認するとよいでしょう。
【参考記事】
この記事の著者

データサイエンティスト
市川 太祐
医師・医学博士。名古屋市立大学客員准教授。データサイエンティスト。データを用いた意思決定に長年取り組む。予防医療から電子カルテデータ、ライフログデータまで幅広い分析経験を持つ。「R言語徹底解説」(共立出版)、「データ分析プロジェクトの手引き」 (共立出版)等、データ分析関連の著書・訳書多数。
「ChatGPT導入・活用支援」はNOB DATAにご相談ください
ChatGPTの導入・活用に課題を感じていませんか?
NOB DATAでは、ChatGPT開発およびデータ分析・AI開発のプロフェッショナルが、多種多様な業界・課題解決に取り組んだ実績を踏まえ、ChatGPTの導入・活用を支援しています。社員向けのChatGPT研修も実施しており、お気軽にお問い合わせください。
ChatGPTを使ったデータ分析の基本